We consolidate performance from both closed-source and open-source MLLM evaluations.
We use deeper-gray to highlight the top result among all models in each sub-task, while
light-gray marks the second-best result.
As the primary results show, there remains a substantial performance gap between both closed- and open-source MLLMs and human-level multi-view understanding.
| Methods |
Avg. |
Attr. |
Cam. Pose |
Count. |
Manip. |
Rel. Dir. |
Rel. Dist. |
| Perf. Against Human (250 Q&As) |
| Human Level | 82.0 | 93.3 | 88.9 | 86.3 | 72.0 | 79.5 | 95.7 |
| GPT-4o | 52.4 | 66.7 | 16.7 | 52.9 | 40.0 | 53.8 | 63.8 |
| Gemini-2.0-Flash | 58.4 | 62.2 | 38.9 | 64.7 | 48.0 | 56.4 | 68.1 |
| Claude-3.7-Sonnet | 52.8 | 60.0 | 38.9 | 37.3 | 38.0 | 56.4 | 80.9 |
| InternVL2.5-38B | 60.8 | 73.3 | 27.8 | 70.6 | 42.0 | 64.1 | 68.1 |
| Qwen2.5-VL-72B | 58.4 | 73.3 | 22.2 | 52.9 | 44.0 | 61.5 | 76.6 |
| Closed-source Models |
| GPT-4o | 47.8 | 66.8 | 35.8 | 43.0 | 42.6 | 38.9 | 51.2 |
| Gemini-1.5-Pro | 47.4 | 59.8 | 33.5 | 39.4 | 45.2 | 38.6 | 55.1 |
| Gemini-1.5-Flash | 46.6 | 62.9 | 43.8 | 35.9 | 43.9 | 33.2 | 52.4 |
| Gemini-2.0-Flash | 52.3 | 68.4 | 33.0 | 64.9 | 41.0 | 41.8 | 58.9 |
| Claude-3.5-Sonnet | 48.2 | 63.2 | 33.0 | 41.8 | 41.2 | 43.5 | 55.3 |
| Claude-3.7-Sonnet | 50.0 | 68.4 | 35.8 | 41.4 | 40.1 | 46.9 | 56.7 |
| Open-source Models |
| DeepSeek-VL2-Small | 45.5 | 65.3 | 27.8 | 39.0 | 42.6 | 32.7 | 51.6 |
| DeepSeek-VL2 | 47.8 | 70.5 | 24.4 | 39.0 | 46.2 | 33.5 | 54.7 |
| InternVL2.5-2B | 41.0 | 59.5 | 15.9 | 42.6 | 34.2 | 30.7 | 48.8 |
| InternVL2.5-4B | 45.8 | 66.6 | 18.2 | 47.8 | 36.6 | 35.8 | 54.7 |
| InternVL2.5-8B | 49.9 | 73.9 | 28.4 | 48.6 | 41.6 | 40.3 | 54.5 |
| InternVL2.5-38B | 55.6 | 80.4 | 31.3 | 56.6 | 45.2 | 49.7 | 58.7 |
| InternVL2.5-78B | 52.5 | 79.4 | 27.3 | 52.6 | 39.7 | 43.5 | 59.3 |
| Qwen2.5-VL-3B | 45.2 | 62.7 | 22.2 | 45.0 | 37.2 | 36.4 | 53.8 |
| Qwen2.5-VL-72B | 55.7 | 77.5 | 29.5 | 55.4 | 43.7 | 54.3 | 60.7 |
| Ovis2-2B | 46.2 | 61.9 | 26.7 | 49.0 | 42.0 | 35.5 | 51.4 |
| Ovis2-4B | 46.6 | 65.5 | 21.6 | 53.4 | 34.0 | 36.1 | 56.9 |
| Ovis2-8B | 49.1 | 70.5 | 17.0 | 49.4 | 43.5 | 41.2 | 54.7 |
| Ovis2-16B | 53.2 | 75.5 | 29.5 | 56.6 | 44.3 | 46.3 | 56.1 |
| Ovis2-34B | 55.3 | 79.4 | 26.7 | 53.8 | 46.2 | 50.6 | 59.7 |
| Cambrian-8B | 39.2 | 59.8 | 19.9 | 33.1 | 33.0 | 33.0 | 43.5 |
| Cambrian-13B | 36.5 | 59.0 | 25.6 | 30.7 | 27.3 | 32.1 | 37.9 |
| Cambrian-34B | 41.9 | 63.7 | 20.5 | 38.2 | 37.2 | 35.2 | 43.7 |
| LLaVA-OV-Qwen2-7B | 45.9 | 64.5 | 22.2 | 39.4 | 44.5 | 35.2 | 52.0 |
| LLaVA-OV-Qwen2-72B | 52.5 | 73.4 | 26.7 | 45.4 | 45.6 | 46.3 | 60.3 |
| LLaVA-Video-Qwen2-7B | 42.8 | 64.8 | 12.5 | 42.2 | 32.6 | 37.2 | 50.8 |
| LLaVA-Video-Qwen2-72B | 53.1 | 73.6 | 27.8 | 46.2 | 45.2 | 46.6 | 61.9 |
Table 1. Evaluation results on All-Angles Bench across closed-source and open-source MLLMs.
Finding 1: Simple tasks for humans like coarse camera pose estimation pose challenges for MLLMs.
While humans achieve near-perfect accuracy on All-Angles Bench, both open- and closed-source MLLMs struggle.
In camera pose estimation, human annotators reach 88.9% accuracy, while top MLLMs like Gemini-2.0-Flash,
Qwen2.5-VL-72B, and InternVL2.5-38B lag by over 50%. Many open-source models perform worse than random guessing,
often failing to align viewpoints or interpret geometric relationships, highlighting a significant gap from human-level reasoning.
Finding 2: Certain open-source MLLMs surpass closed-source ones in orientation-sensitive tasks.
Interestingly, Ovis2-34B and Qwen2.5-VL-72B outperform closed-source models like Gemini-2.0 and Claude-3.7-Sonnet
in object manipulation and relative direction.
Qwen2.5-VL-72B benefits from robust video understanding and fine-grained visual grounding, excelling at tracking object re-orientation across views.
The success of open-source models suggests that domain-specific refinements, such as video-focused training,
can enhance orientation and geometric reasoning, offering insights for improving multi-view MLLMs.
| 3D Spatial Reasoning Models |
Avg. |
Attr. |
Cam. Pose |
Count. |
Manip. |
Rel. Dir. |
Rel. Dist. |
| VG-LLM (Zheng et al. 2025) | 33.7 | 56.7 | 16.5 | 26.3 | 30.0 | 26.9 | 34.2 |
| AoTD (Shi et al. 2025) | 36.8 | 41.5 | 32.4 | 27.9 | 37.6 | 26.7 | 45.5 |
| VLM-3R (Fan et al. 2025) | 40.3 | 56.1 | 22.7 | 39.4 | 35.9 | 30.9 | 45.6 |
| CoF (Ghazanfari et al. 2025) | 47.8 | 75.7 | 35.8 | 41.4 | 38.7 | 38.7 | 49.0 |
| SpaceR (Ouyang et al. 2025) | 49.7 | 72.8 | 51.1 | 46.2 | 41.2 | 38.1 | 49.4 |
Table 2. Performance of 3D specialized spatial reasoning MLLMs on All-Angles Bench.
Finding 3: 3D specialized spatial reasoning MLLMs close the gap but are often limited to specific subtasks.
Recent MLLMs purpose-built for spatial reasoning, such as SpaceR, VLM-3R, and AoTD, achieve notable gains across spatial subtasks.
In particular, SpaceR scores 51.1 on Camera Pose Estimation, surpassing many general-purpose MLLMs.
However, their strengths are often confined to the specific subtasks they explicitly target.
These results suggest that while injecting spatial priors or specialized architectures helps, it does not yet fully solve the general multi-view challenge.


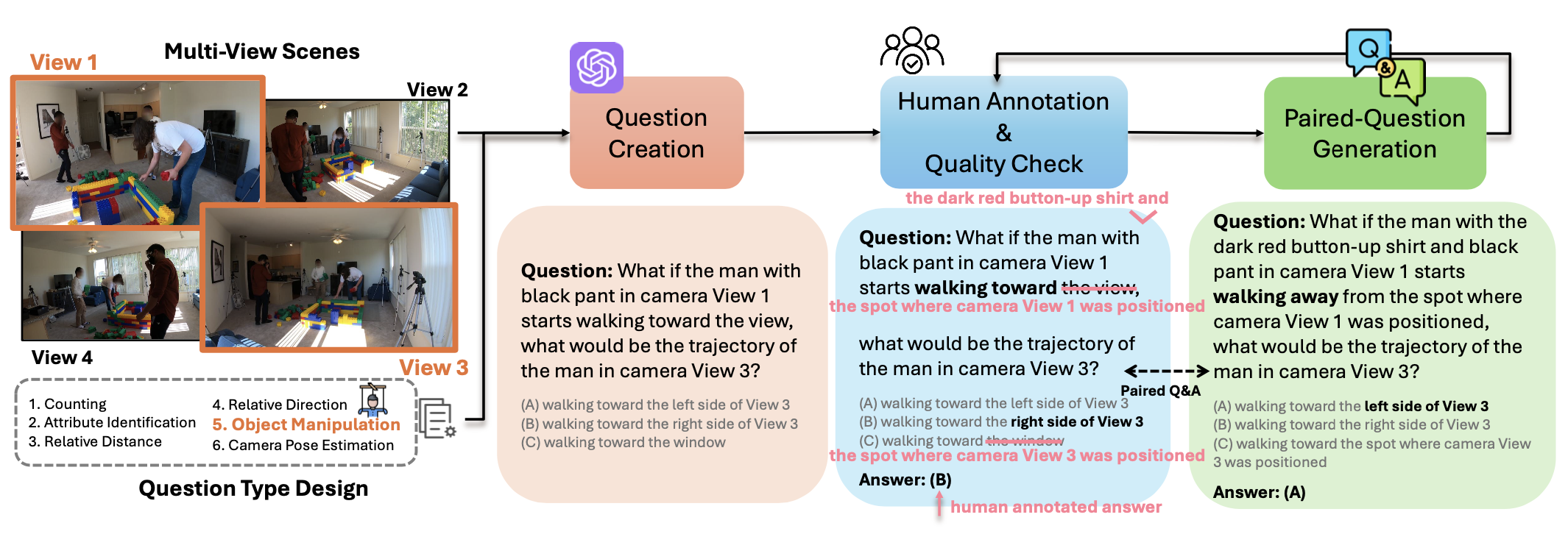
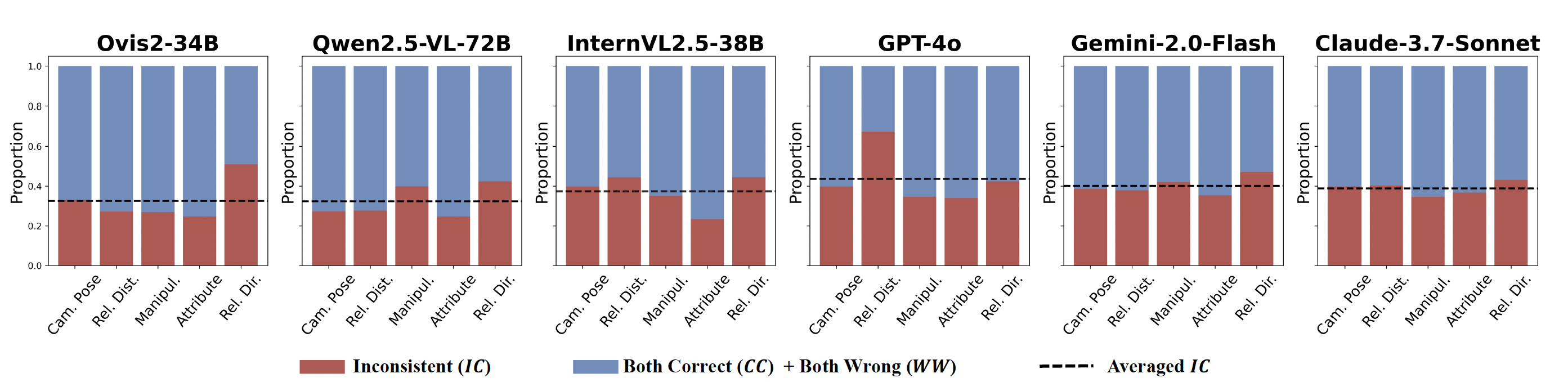

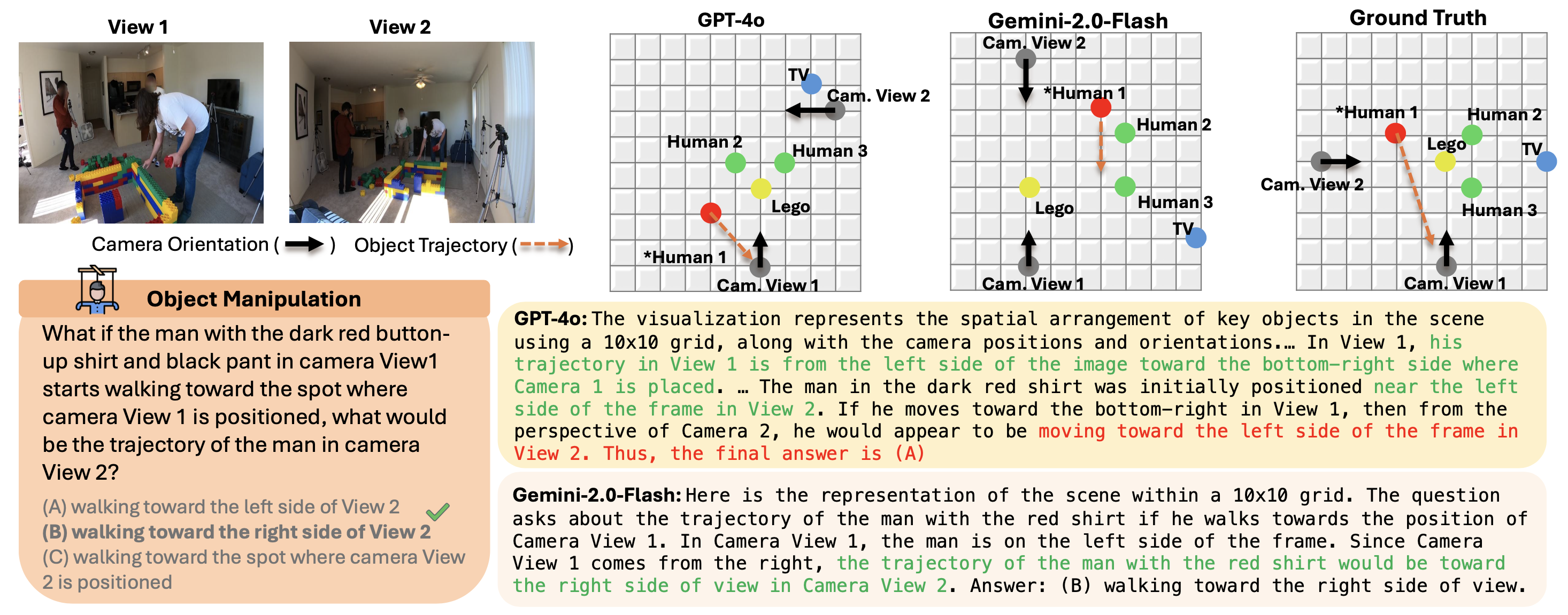

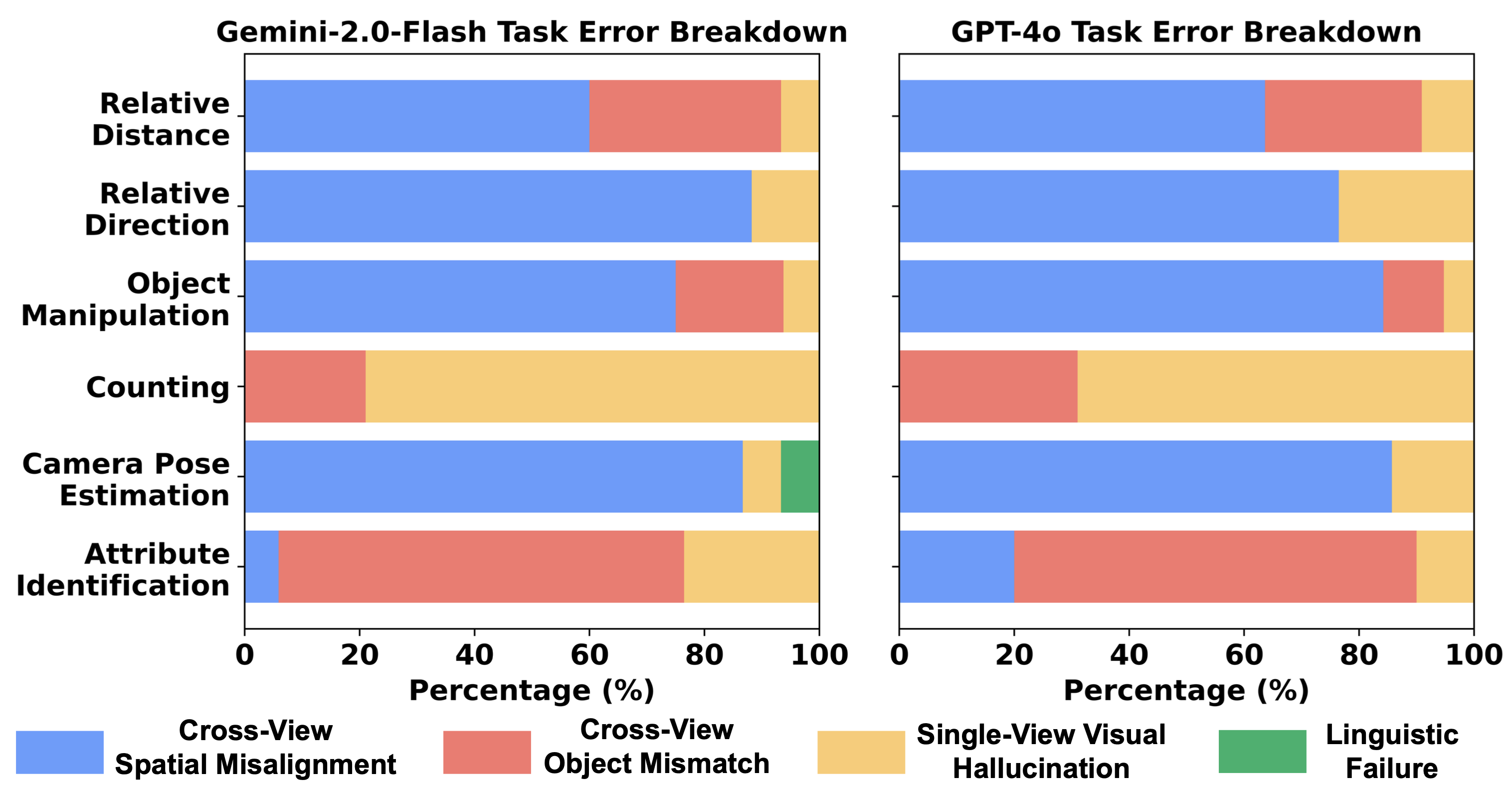
 Seeing from Another Perspective:
Seeing from Another Perspective: