
@inproceedings{yeh2022decoupled,
title={Decoupled Contrastive Learning},
author={Yeh, Chun-Hsiao and Hong, Cheng-Yao and Hsu, Yen-Chi and Liu, Tyng-Luh and Chen, Yubei and LeCun, Yann},
booktitle={European Conference on Computer Vision (ECCV)},
pages={668--684},
year={2022}
}
TL;DR
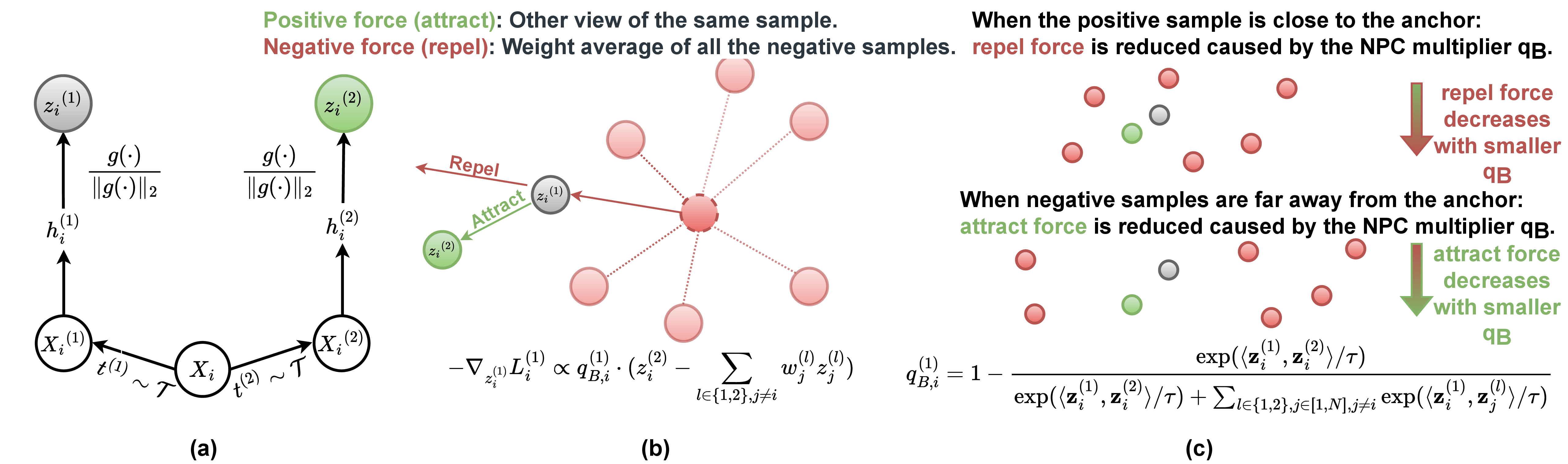
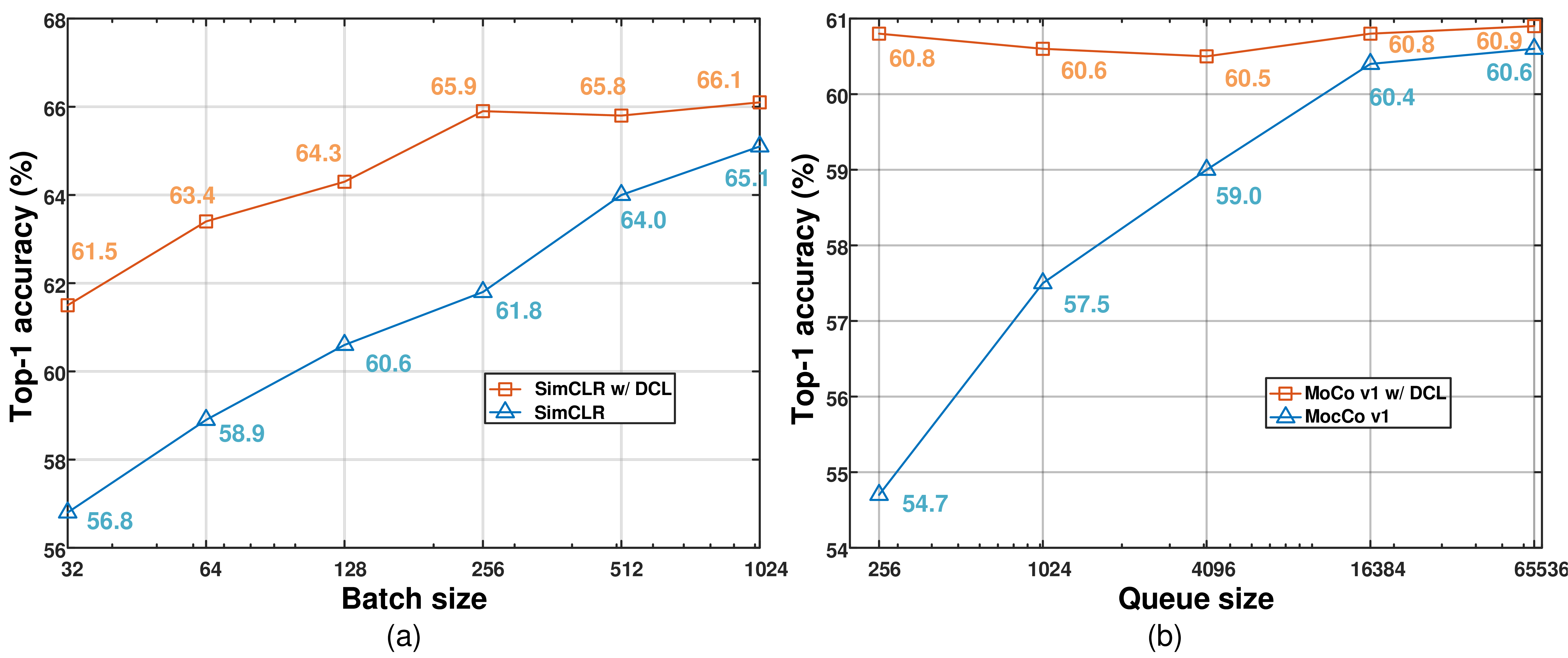
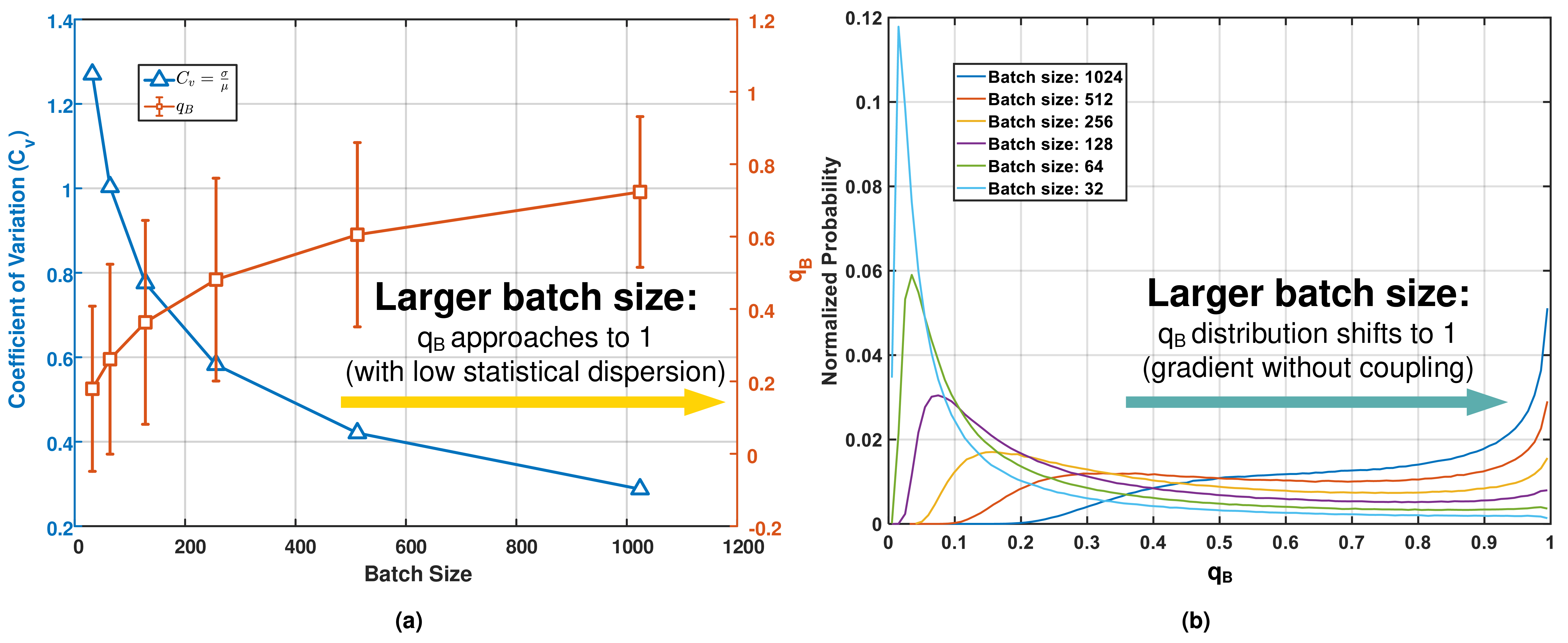
- The problem: InfoNCE has a hidden coupling between positive and negative samples (the NPC effect) that reduces learning efficiency, especially at small batch sizes.
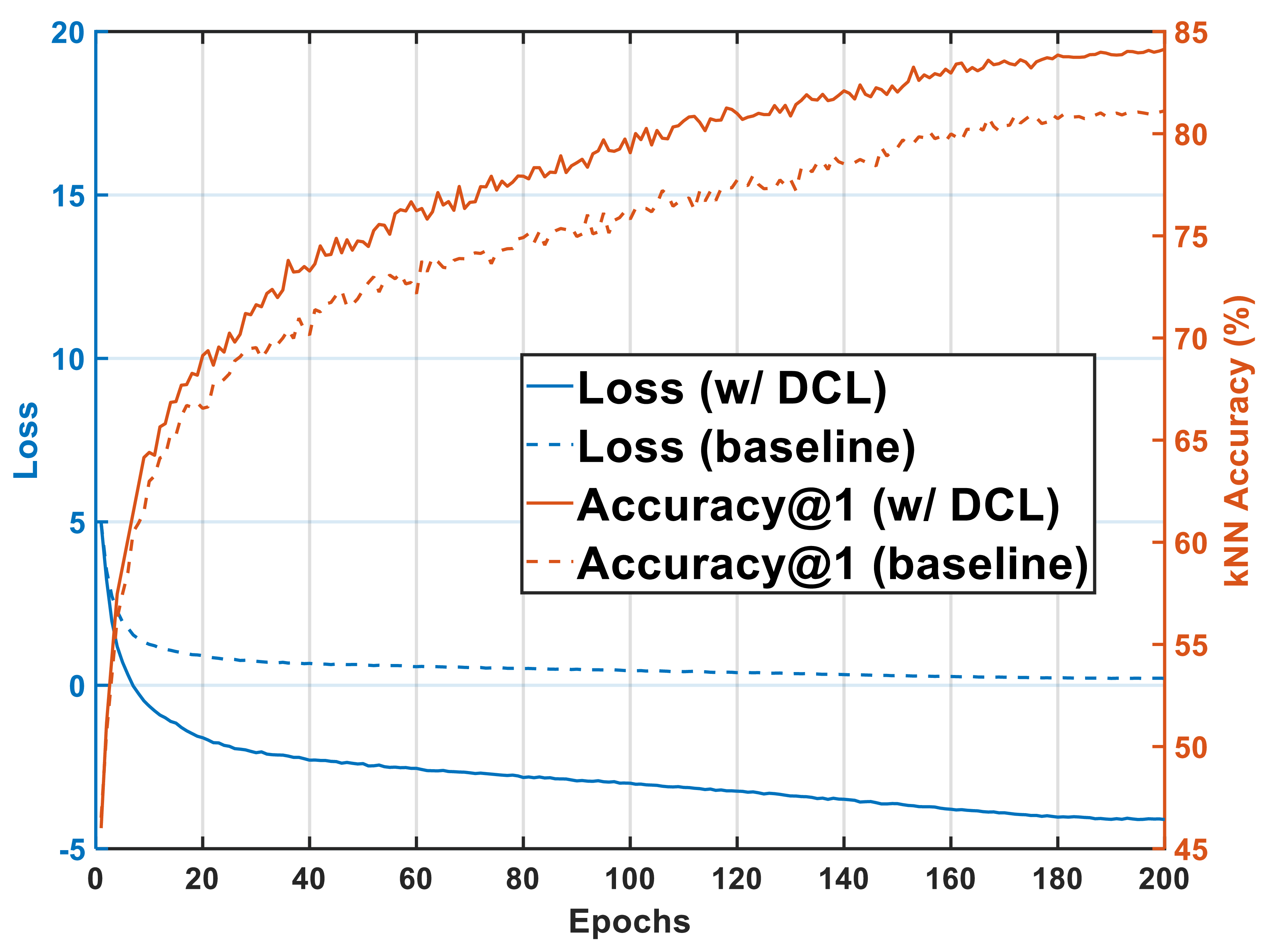
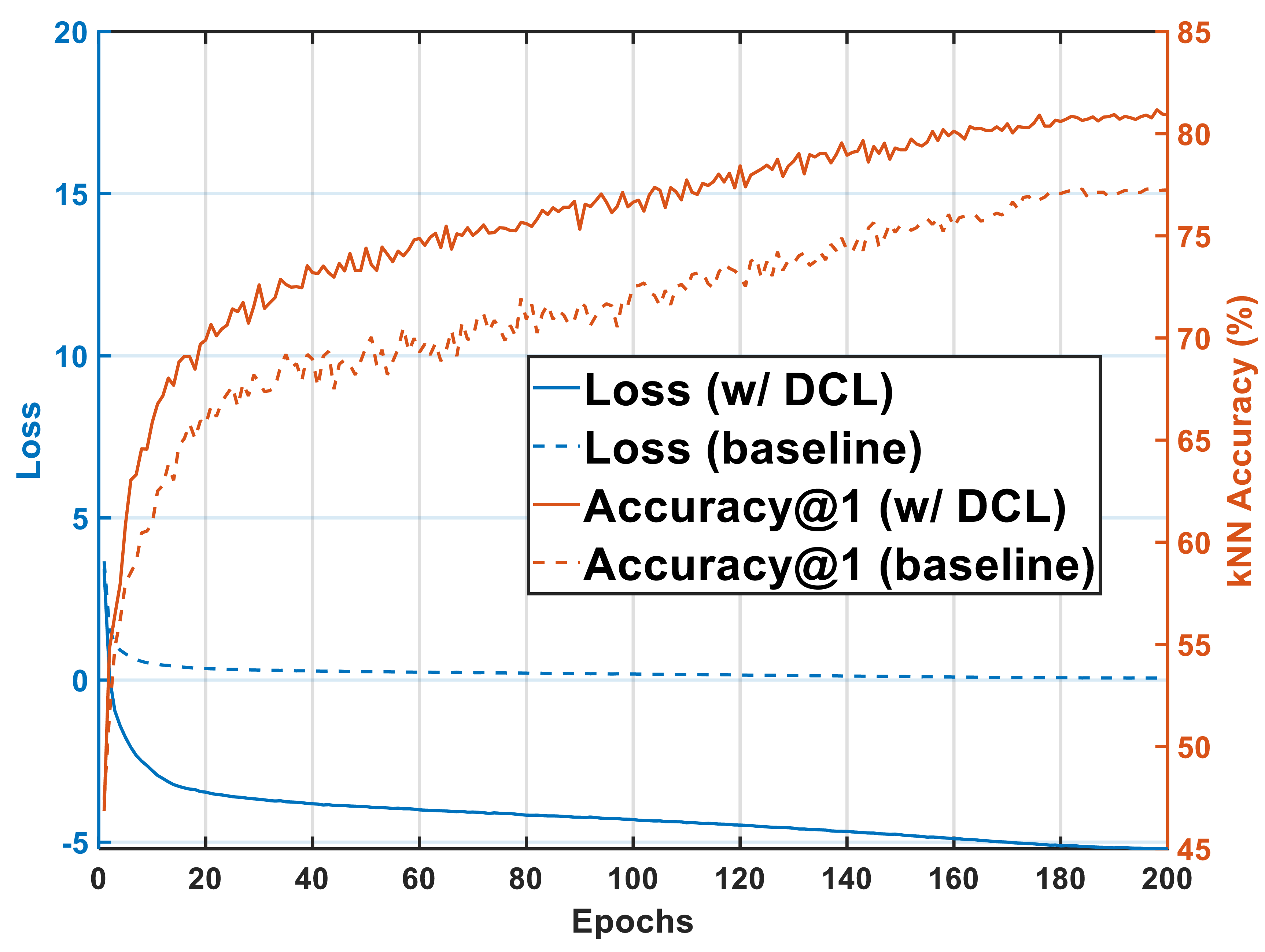
- Our solution: DCL removes the positive term from the denominator, decoupling gradients and eliminating batch-size sensitivity.
- The payoff: +6.4% on ImageNet-1K with batch 256, new SOTA 72.3% combined with NNCLR.