






@inproceedings{yeh2026gasp,
title={Beyond 3D VQAs: Injecting 3D Spatial Priors into Vision-Language Models for Enhanced Geometric Reasoning},
author={Yeh, Chun-Hsiao and Qian, Shengyi and Wang, Manchen and Ma, Yi and Tighe, Joseph and Xiao, Fanyi},
booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}
TL;DR
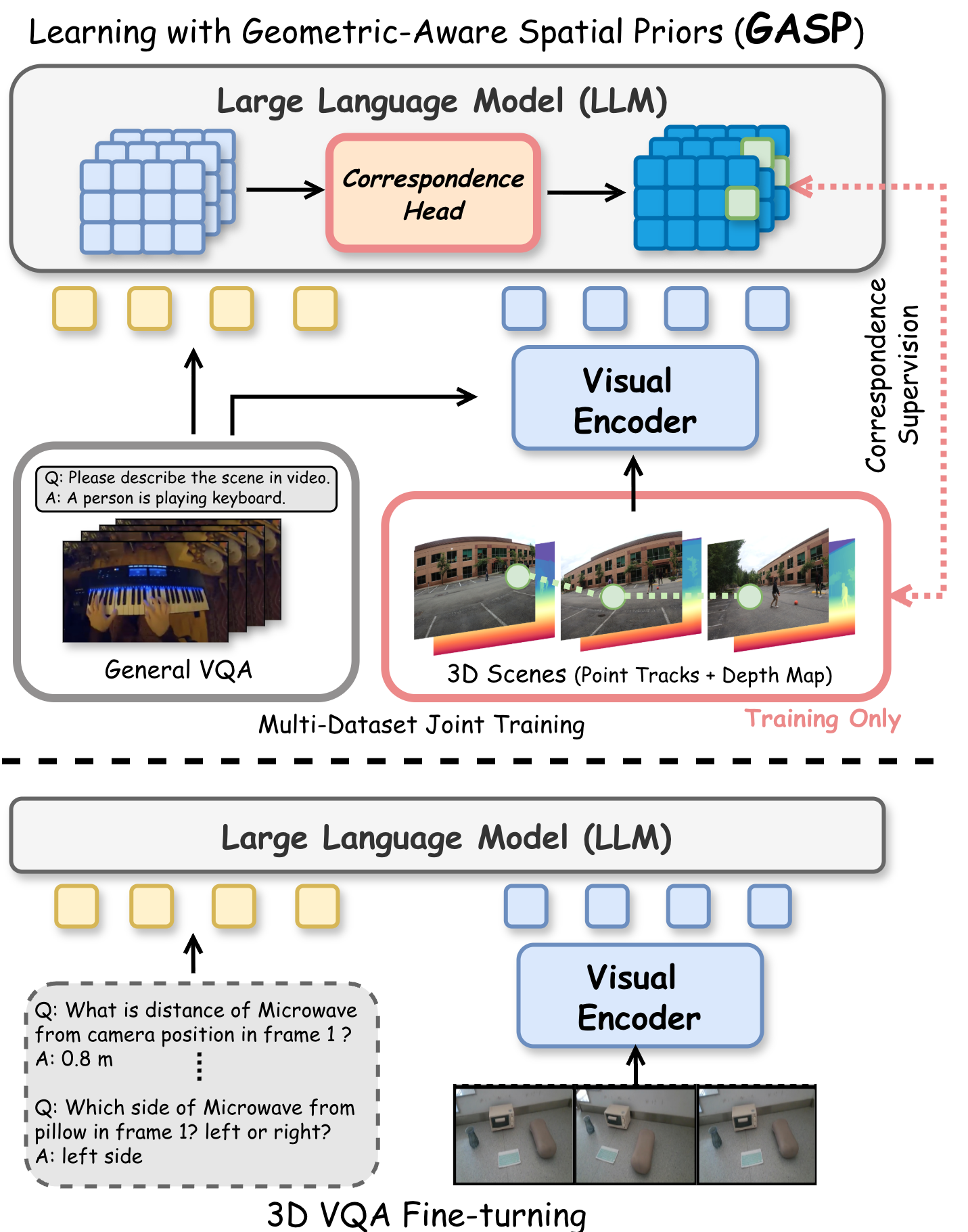
- Why it matters: VLMs' internal visual representations have near-zero geometric consistency. They can't reliably tell if the same object appears in two different views. Existing fixes (VQA fine-tuning, 3D encoders) either overfit or add rigid modules.
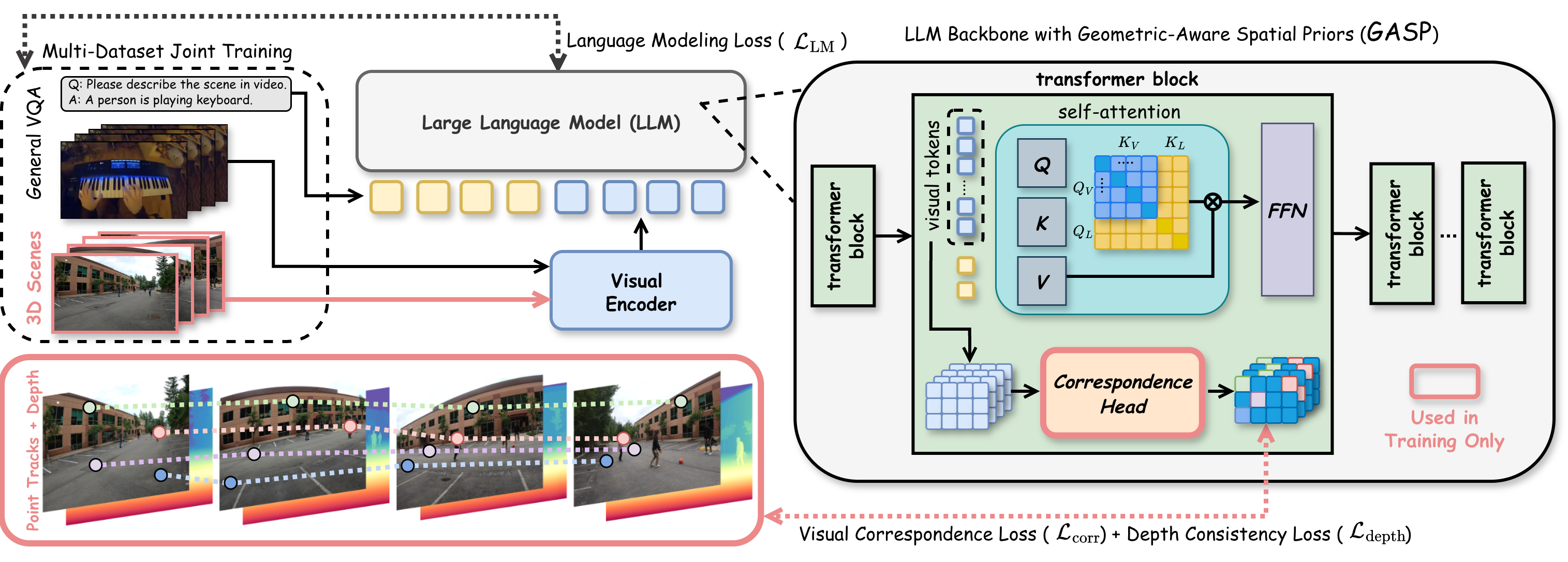
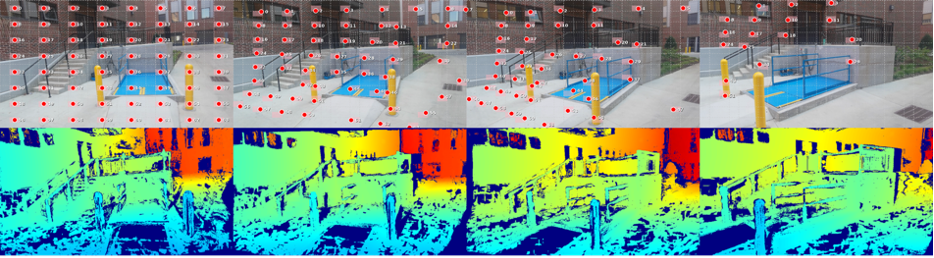
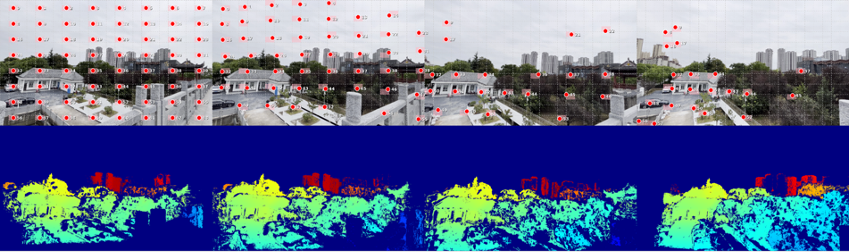
- Our approach: Instead of memorizing QA pairs, GASP teaches the LLM fundamental geometry through point correspondence + depth consistency supervision at every transformer layer. The training head is discarded at inference with zero overhead.
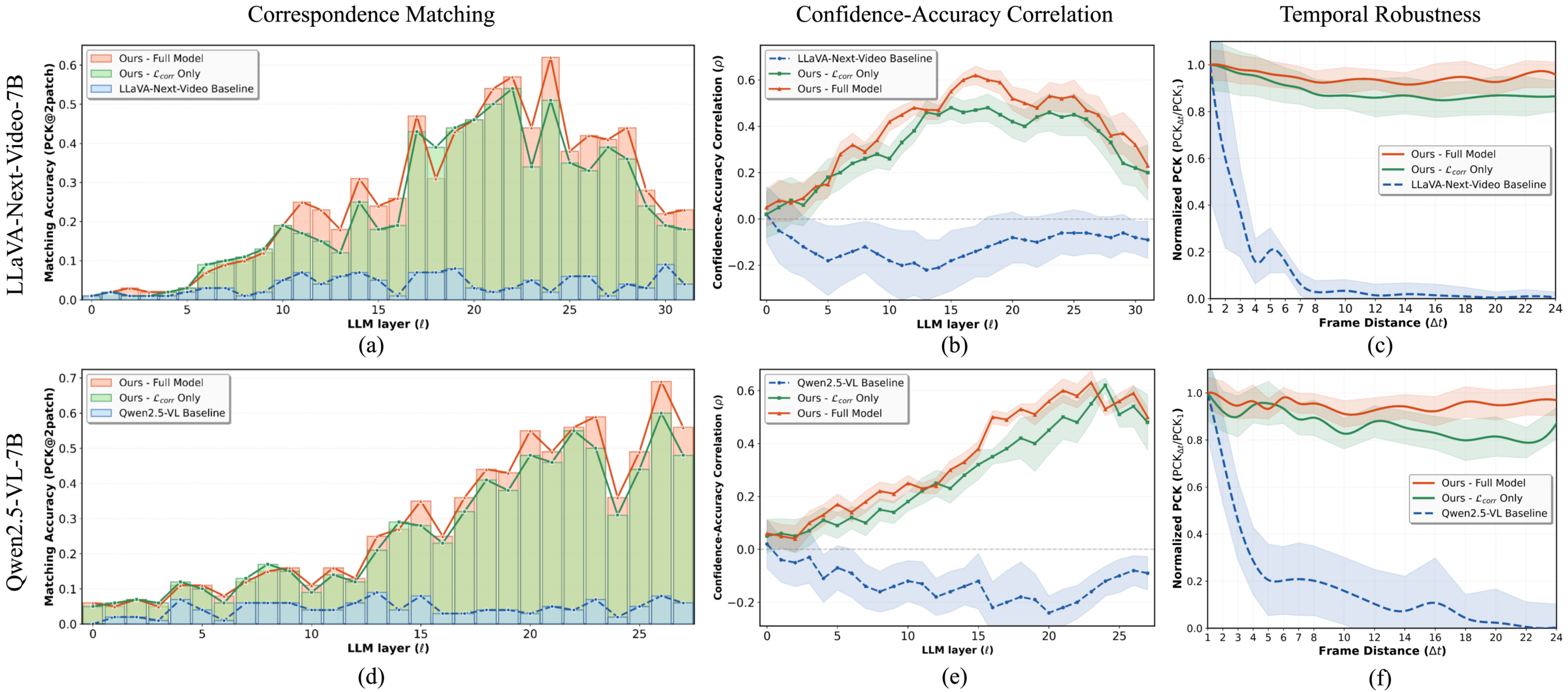
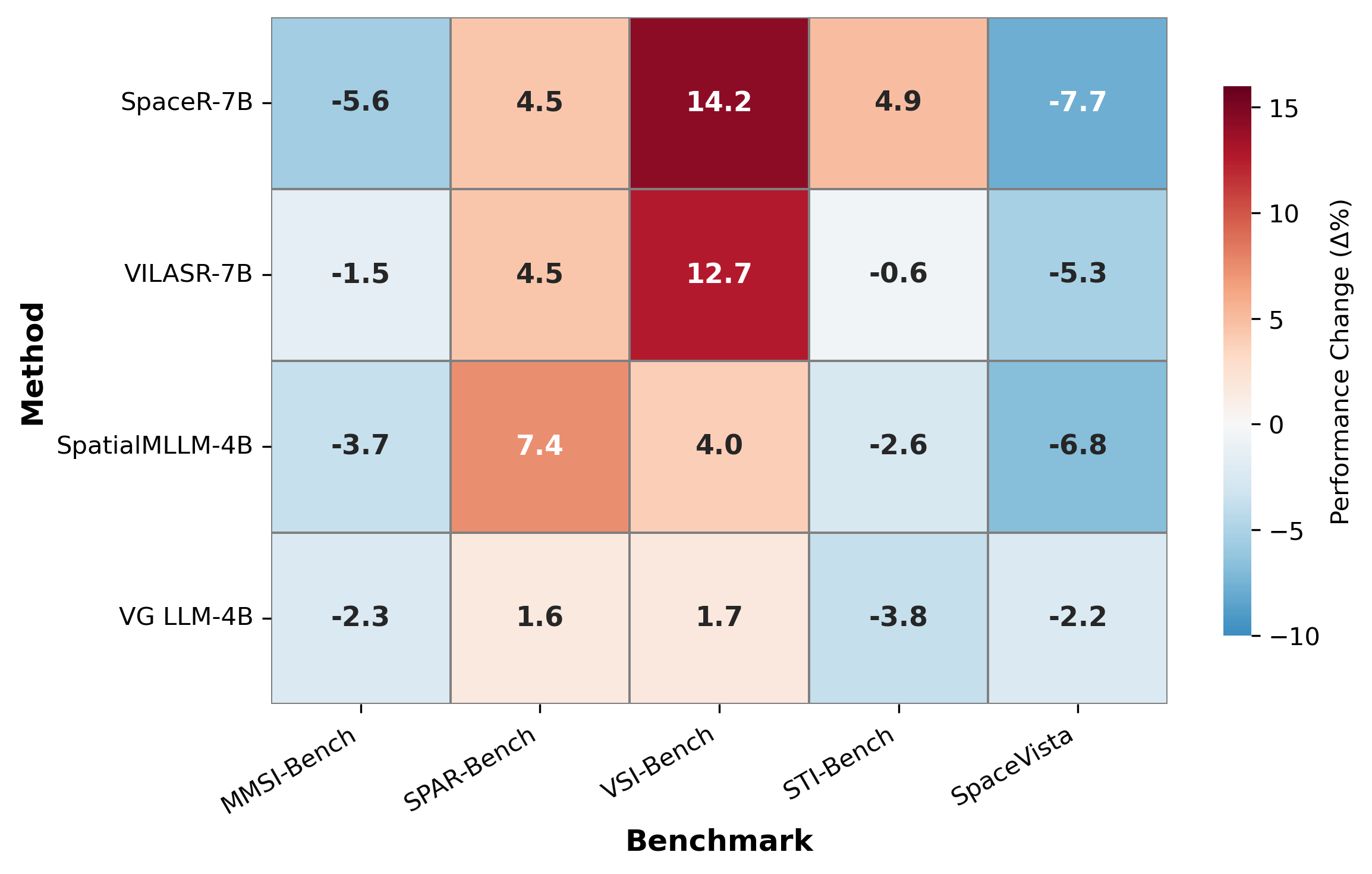
- The payoff: Internal correspondence jumps from <5% to 70%+. Downstream: +18.2% on spatial reasoning, +29.0% on object counting, all without any 3D VQA data.