

@misc{yeh2024gen4gen,
title={Gen4Gen: Generative Data Pipeline for Generative Multi-Concept Composition},
author={Chun-Hsiao Yeh and Ta-Ying Cheng and He-Yen Hsieh and Chuan-En Lin and Yi Ma and Andrew Markham and Niki Trigoni and H. T. Kung and Yubei Chen},
year={2024},
eprint={2402.15504},
archivePrefix={arXiv},
primaryClass={cs.CV}
}Our Data Creation Pipeline: Gen4Gen
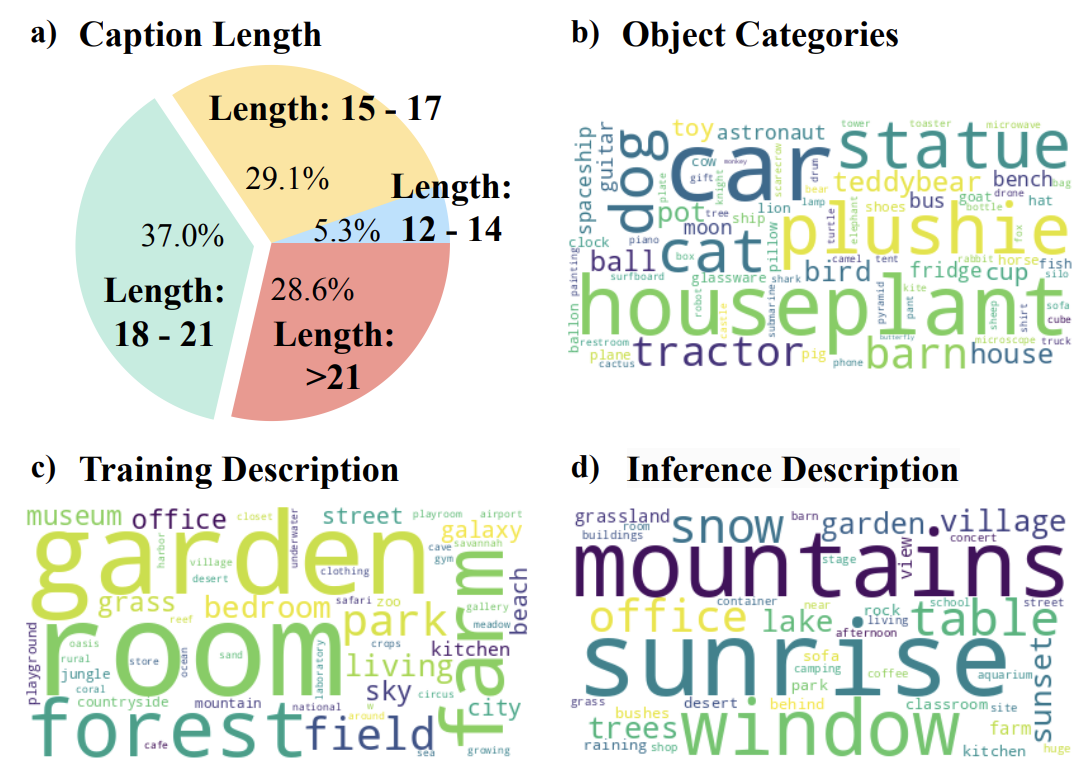
Given source images representing multiple concepts, our Gen4Gen leverages recent advancements in image foreground extraction, LLMs, MLLMs, and inpainting to compose realistic, personalized images and paired text descriptions, producing the MyCanvas Dataset.
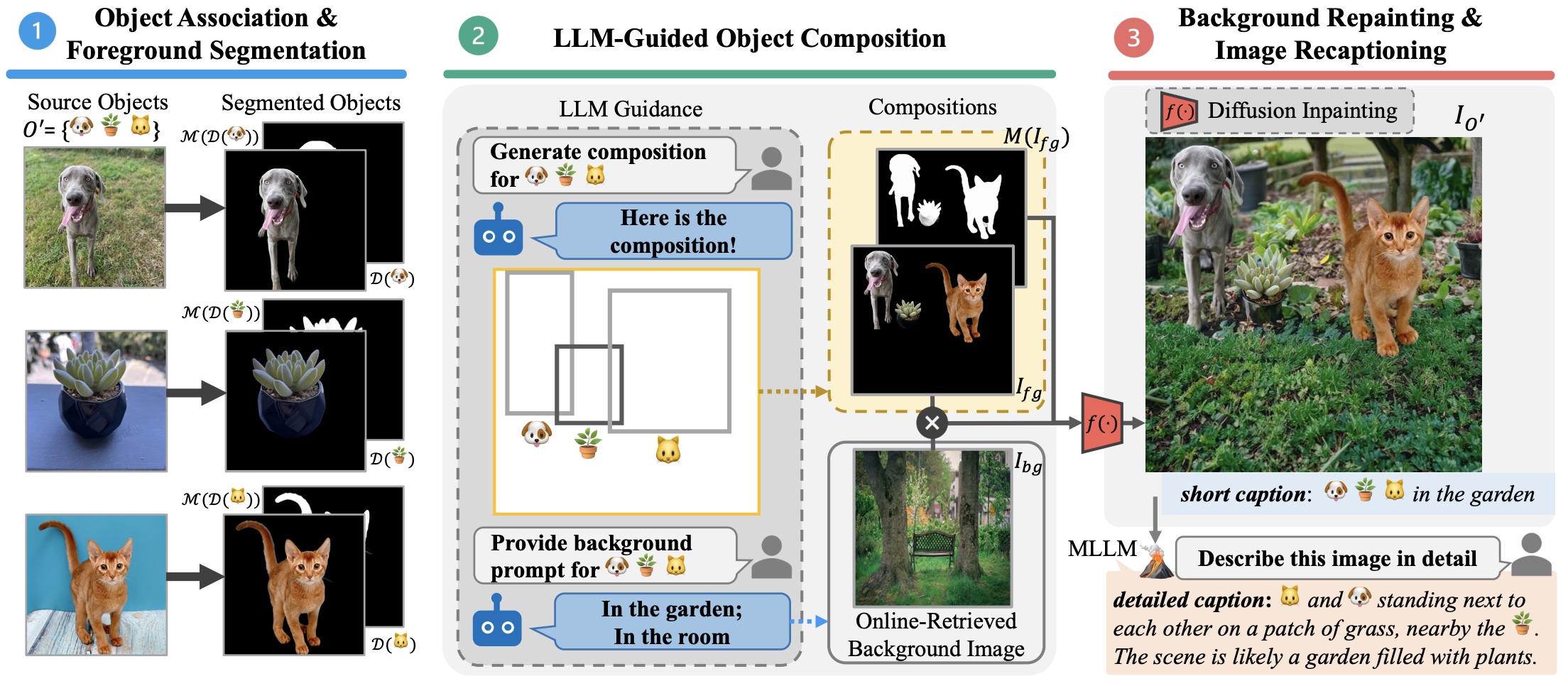
Figure 2. Semi-Automated Data Creation Overview: Given source images representing multiple concepts, Gen4Gen leverages image foreground extraction, LLMs, MLLMs, and inpainting to compose realistic, personalized images and paired text descriptions.