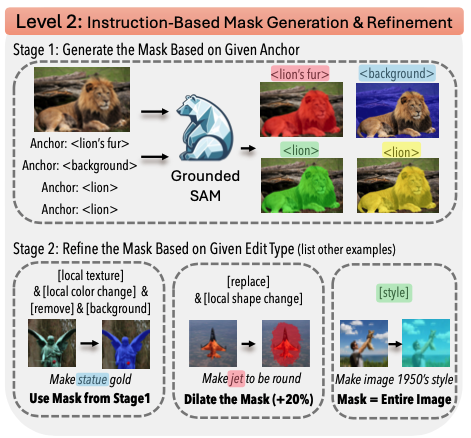
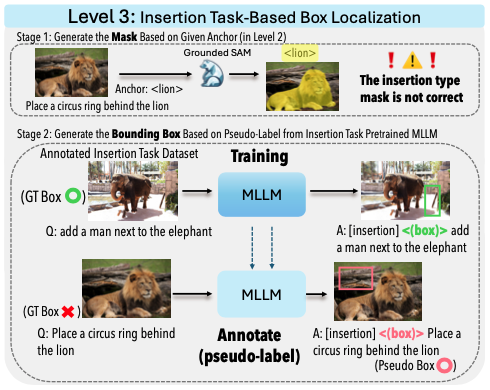
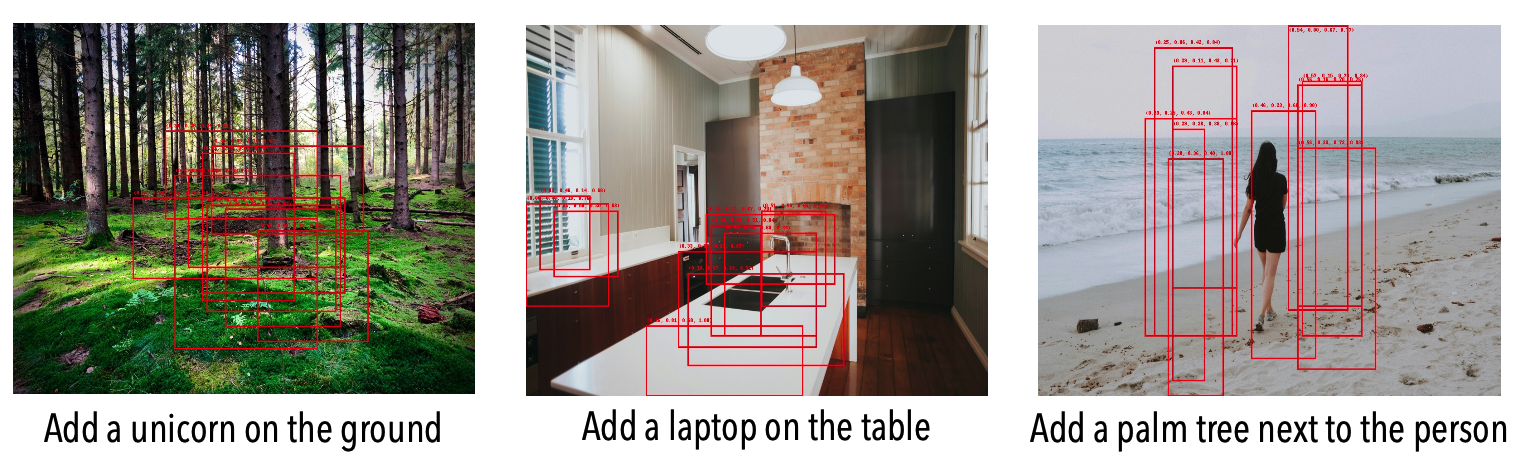
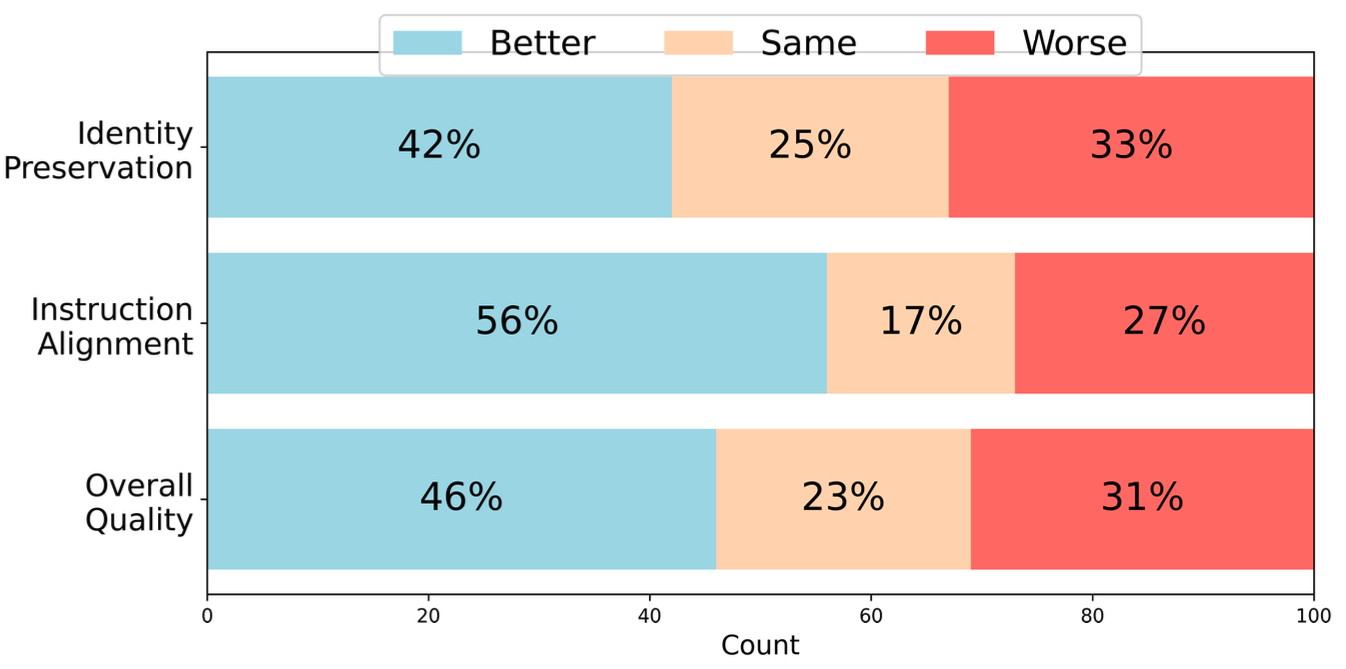
Instruction-based image editing has seen rapid progress, yet existing methods often struggle with complex, multi-step instructions that involve multiple objects and require precise spatial understanding. We introduce X-Planner, a MLLM-based framework that decomposes complex image editing instructions into a sequence of interpretable and simpler sub-instructions with region-aware editing guidance: segmentation masks and bounding boxes. X-Planner is composed of a MLLM and a segmentation decoder, which together decompose complex instructions into sub-tasks and generate precise segmentation masks or bounding boxes. By dynamically selecting from a pool of specialized editing models, X-Planner performs localized edits in an iterative and interpretable way, enabling fine-grained, multi-object, and multi-step visual transformations with minimal manual effort. We demonstrate that integrating X-Planner with existing editing models (InstructPix2Pix* and UltraEdit) significantly improves both object identity preservation and instruction alignment on the COMPIE benchmark. Note that we demonstrate the flexibility of X-Planner where we train based on both closed-source (GPT-4o) and open-source (Pixtral-Large) model generated datasets.